An innovative, Industrious and capable engineer. Software engineer at Acer. Focused on "Spatial Computing" and applying "Deep Learning" and "Computer Vision" solutions for our products.
✓ Specialize in "Deep Learning" and "Computer Vision"
✓ About 3 Years Software Engineer, solid C++ / Python algorithm development experience
✓ Develop computer vision and machine learning algorithms for "SpatialLabs™ " (TW)
(Glasses-free stereoscopic 3D solutions)
- Delivers glasses-free 3D sensation via advanced optical, display, and eye-tracking technology. And
utilizes AI technology to instantly fully convert 2D content into stereo 3D
✓ Design, deploy and optimize applications and machine learning algorithms
✓ 15 Patents applied
✓ 350+ hours Taiwan AI Academy9th certified & won semester presentation 1st

The rapid development of autostereoscopic 3D monitors offers users a brand-new 3D visualization experience. However, this technology only works with 3D content inputs like side-by-side images. Most images and videos on the internet are 2D single-view content, which makes it difficult for the technology to gain widespread popularity. This project uses "Machine Learning" and "Computer Vision" to instantly convert 2D content into stereo 3D
Achievement:
✓ Develop computer vision and machine learning algorithms for "SpatialLabs™ " (TW)
- Delivers glasses-free 3D sensation via optical, display, and eye-tracking technology. And utilizes AI technology instantly convert 2D content into stereo 3D
✓ Deploy and optimize "Depth Estimation" AI solutions on mobile devices using Pytorch (Libtorch) / Windows ML / OpenVINO / ONNX Runtime
✓ Machine learning model quantization, and deploy solutions on VPU (AI chip)
✓ Experience with GPU accelerated computing (CUDA kernel function) for image processing
✓ Experience with OpenCV & Direct3D for image processing
✓ Experience with product development and deployment strategies with C++ / Python. And familiar Window Installers
✓ Cooperate with Intel & ITRI
✓ Patents:
- Stereo Image Generation Method and Electronic Apparatus using the Same (TW [TWM626646U] / US [US20220286658A1] / CH), 2020
- Stereoscopic Image Playback Apparatus (TW [TWM630947U] / EU / CH), 2021
- Stereo Image Generating Device (TW [TWM628629U] / US), 2021
- Computer Architecture for 3D Display Devices with Side-by-Side Generation (TW / US / CH), 2022 [Under verification]
- Multiview Rendering Pipeline for Side-by-Side images in 3D Display Devices (TW / US / CH), 2022 [Under verification]
- Tree-Dimensional View in Devices Without 3D Display Using Eye Tracking (TW / US /CH), 2022 [Under verification]
- Depth Enhancement Using Face Landmark Detection (TW), 2022 [Under verification]
- Multithread Architecture for Three-Dimensional Image Generation (TW), 2022 [Under verification]
Generate stereoscopic images from monocular images instantly
Generate stereoscopic images from monocular images instantly (side-by-side view)

Monocular depth estimation using convolutional neural network for stereoscopic image generation
Keywords :
Deep Learning, Convolutional Neural Networks, Computer Vision, 3D, Quantization
Pytorch (Libtorch), Windows ML, TensorRT, OpenVINO, ONNX Runtime, D3D11, CUDA Kernel Function, OpenCV
C++, Python
As mentioned, there is no need to generate images if the source is already stereoscopic. However, if the source is single-view images, stereoscopic images need to be generated. In order to make the system more intelligent, Using "Machine Learning" to automatically detect whether the content is 3D or not.
Achievement:
✓ cooperate with ITRI
✓ Patents:
- Side by Side Image Detection Method and Electronic Apparatus using the Same (TW [TW202236207A] / US [US20220284701A1] / CH), 2020
- SBS Detection by Stereo Matching (TW / US / CH / EU), 2022 [Under verification]

Detect content is a stereo image or not
Keywords :
Deep Learning, Convolutional Neural Networks, Computer Vision, Feature Extraction
keras, Tensorflow, OpenCV
Python, C++
Service robots are appearing more and more in our daily lives. The key technologies for service robots involve many fields, including navigation, system control, mechanism modules, vision modules, voice modules, and artificial intelligence. In this research, we present a learning-based mapless motion planner that saves us from using traditional methods like "SLAM" to create maps and allows for navigation.
Achievement:
✓ Develop and deploy "Deep Reinforcement Learning" algorithms
✓ Optimize the model by batch normalization to prevent the gradient from vanishing
✓ Has 100+ stars repository on Github
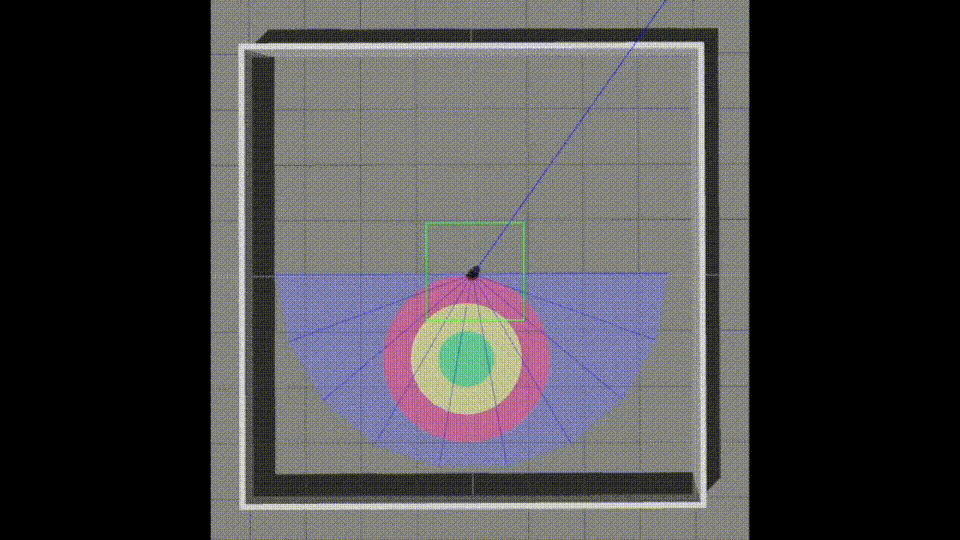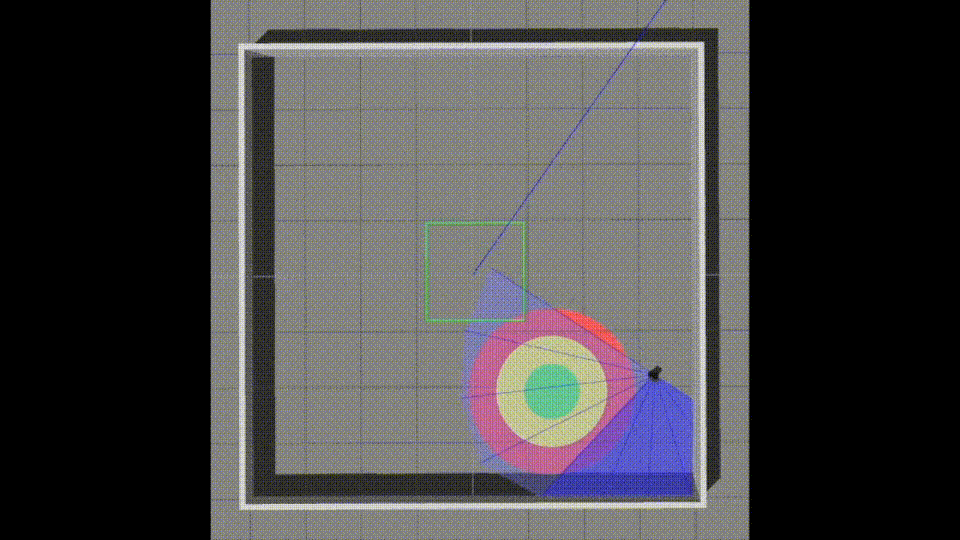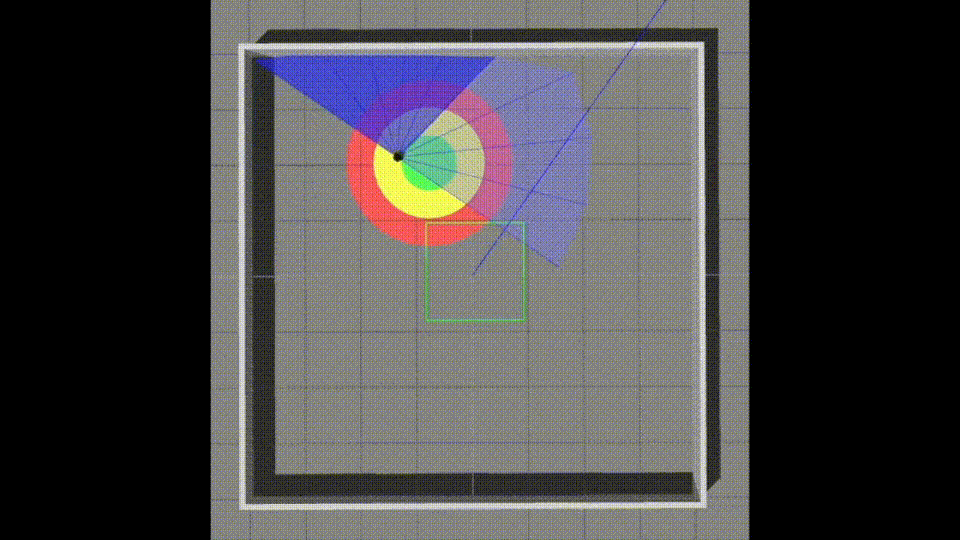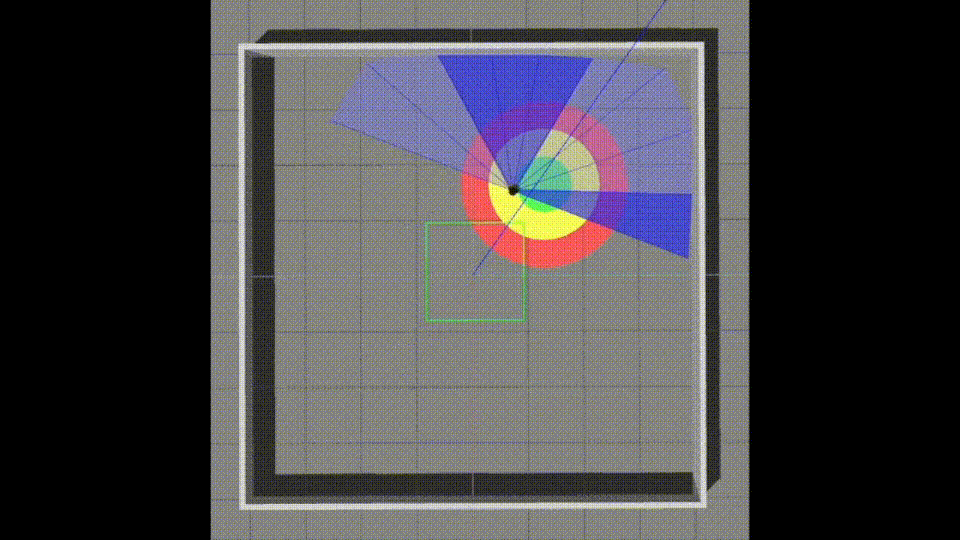
Teach robots how to reach goals without a map
Keywords :
Deep Reinforcement Learning (DRL), Deep Deterministic Policy Gradient (DDPG), Motion Planner, Navigation
ROS, Tensorflow
Python
Scanning QR codes is easy with a mobile phone. But if the QR code is displayed on a computer screen, it becomes a different scenario. Most people would use their phone to scan the code and then send the URL to themselves or crop the QR code and use a QR code decoder to get the URL. This process is complicated and frustrating. To solve this problem, we have developed a service that uses machine learning to detect QR codes on the user's screen and decode the QR code of interest.
Achievement:
✓ Experience with deploy "Object detection" algorithms
✓ Model quantization and deploy with inference engine - OpenVINO
✓ Patents:
- Real-time background QR code detection and decoding (TW), 2022 [Under verification]

QR code detection using object detection model
Keywords :
Deep Learning, Convolutional Neural Networks, Computer Vision, Object Detection, YOLO
Pytorch, OpenVINO, ONNX Runtime, OpenCV
Python, C++
Have you ever seen an outfit from a KOL on social media that you liked, but had trouble finding something similar? In this project, we use "Machine Learning" and "Computer Vision" to develop a system that can find the most similar clothes in a database based on the user's input images.
Achievement:
✓ First place in the semester presentation contest of Taiwan AI Academy
✓ Deploy "Segmentation" and "Feature Extraction" algorithms
✓ Integrate with Line Bot

Base on user input finds the most similar item(clothes) in the database
Keywords :
Deep Learning, Convolutional Neural Networks, Computer Vision, Segmentation, Feature Extraction
Pytorch, Tensorflow, Keras, OpenCV
Python
Augmented reality (AR) has seen rapid growth in recent years, resulting in more companies developing AR devices and applications, such as Microsoft's Hololens. However, most current AR applications are used for entertainment purposes. In order to increase productivity with AR, we have come up with a new idea: getting more virtual screens through AR glasses. This way, users don't have to spend a lot of money on physical monitors.
Achievement:
✓ Develop and deploy "Computer Vision" algorithms for AR application
✓ Co-worked with ITRI
✓ Patents:
- Augmented Reality Screen System and Augmented Reality Screen Display Method (TW [TWI757824B] / US [US11328493B2] / CH), 2020
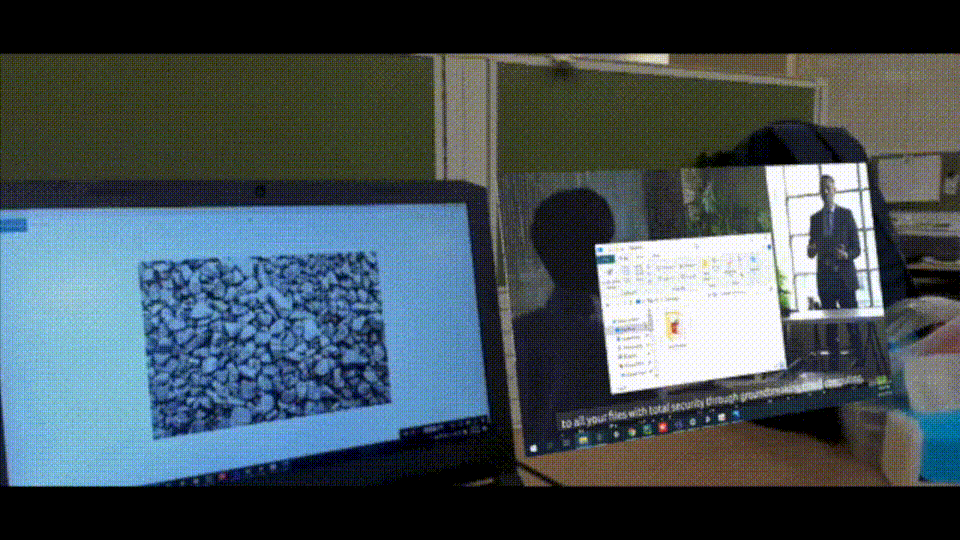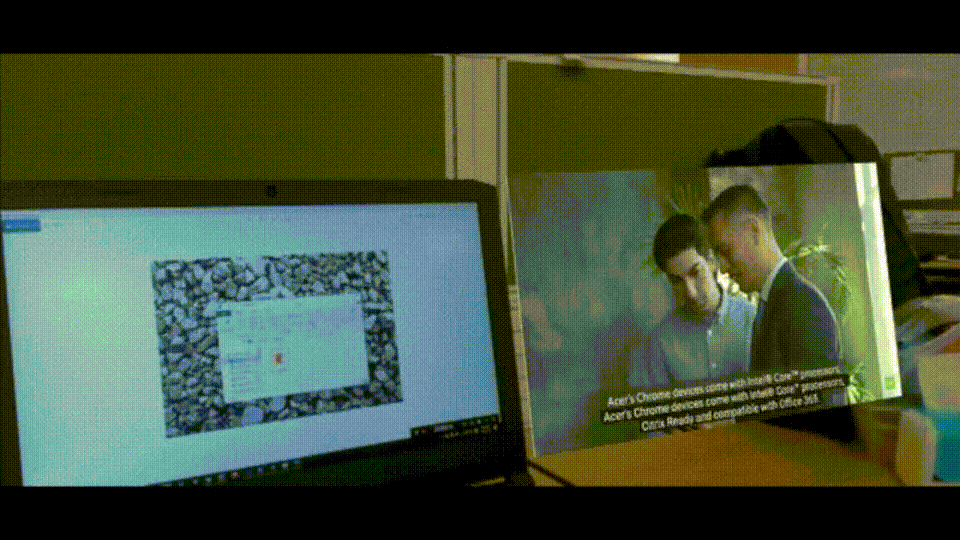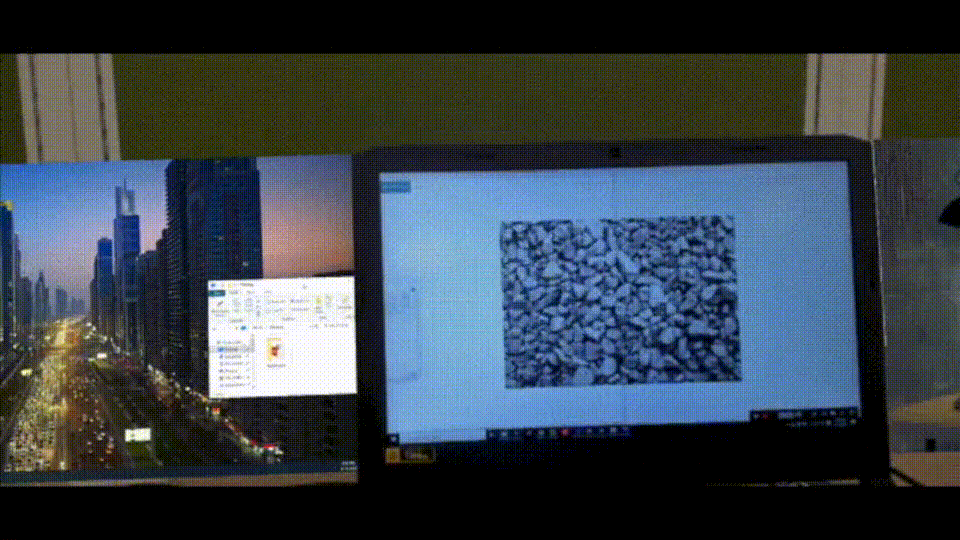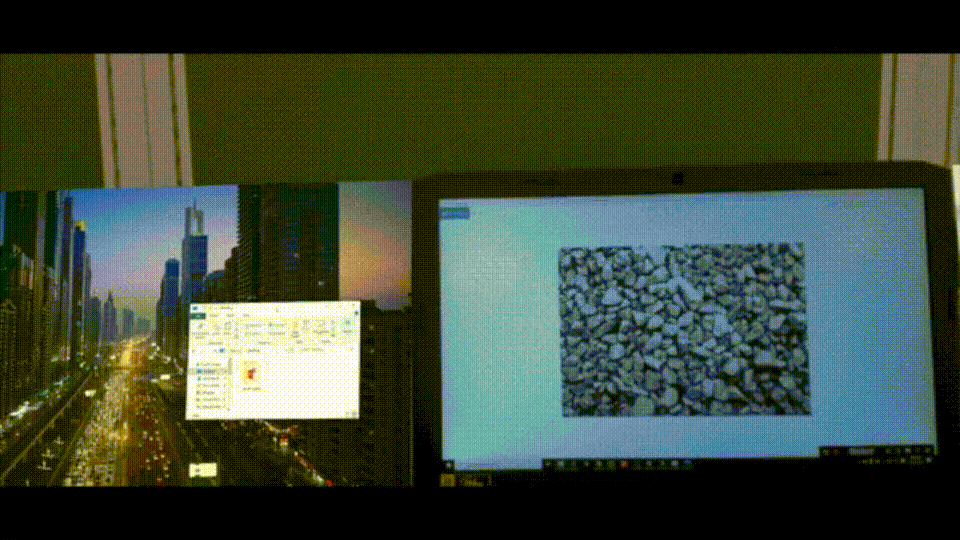
Create a virtual monitor by AR device
Keywords :
Augmented reality (AR), Computer Vision
OpenCV, Unity
Python, C#
Landmark detection is typically used in facial tracking. In this project, we apply the same concept to detect landmarks of interest to calculate the pose of an object.
Achievement:
✓ Research and deploy machine learning algorithms for "Landmark Detection"

Detecting landmark which we are interested in
Keywords :
Deep Learning, Convolutional Neural Networks, Landmark Detection, Pose Estimation, Computer Vision
Pytorch, OpenCV
Python
Localization is crucial for navigation. SLAM has a good performance in indoor localization. Commonly used sensors are mainly divided into lasers or cameras. The advantage of laser SLAM is its high localization accuracy. However, the lack of image information leads to restrictions on some applications. Visual SLAM relies on RGB image and depth map. The disadvantage is that a large number of features extracting and matching, cause a large amount of computation. Therefore, this research will focus on the pose estimation only by RGB image, without features extracting and matching.
Achievement:
✓ Thesis: A Convolutional Neural Network for Real-Time Robot Pose Estimation by RGB Image
✓ Develop "Pose Estimation" machine learning algorithms and deploy on "TurtleBot"
✓ Experience with SLAM for training data collection
✓ Experience with ROS
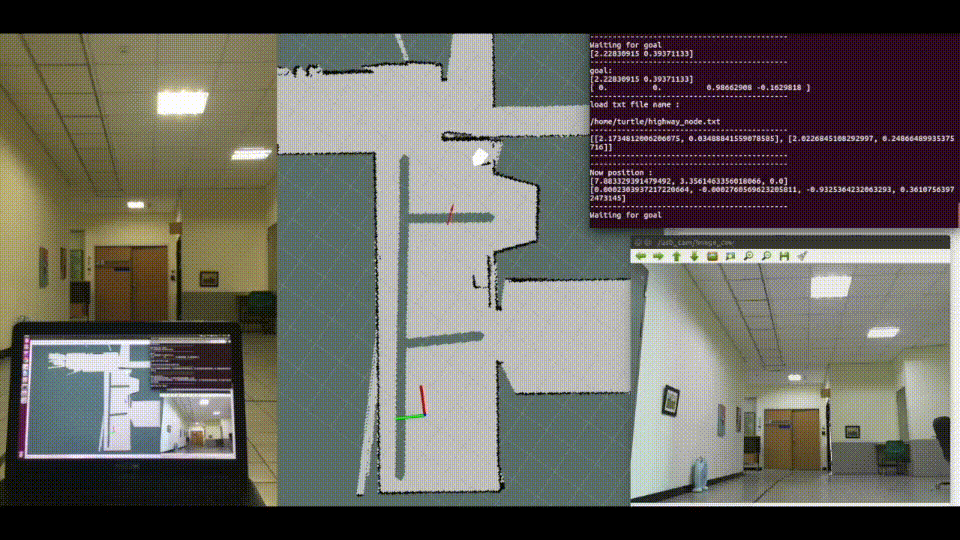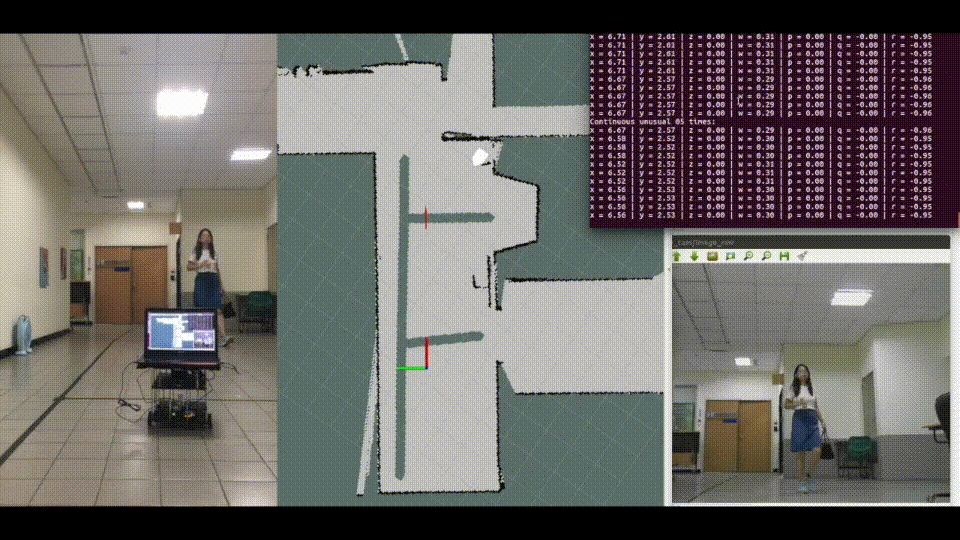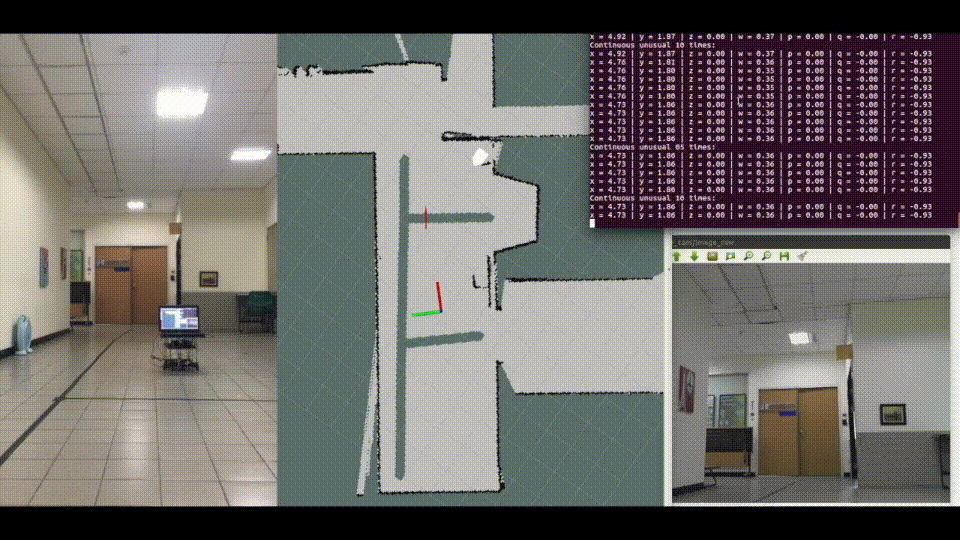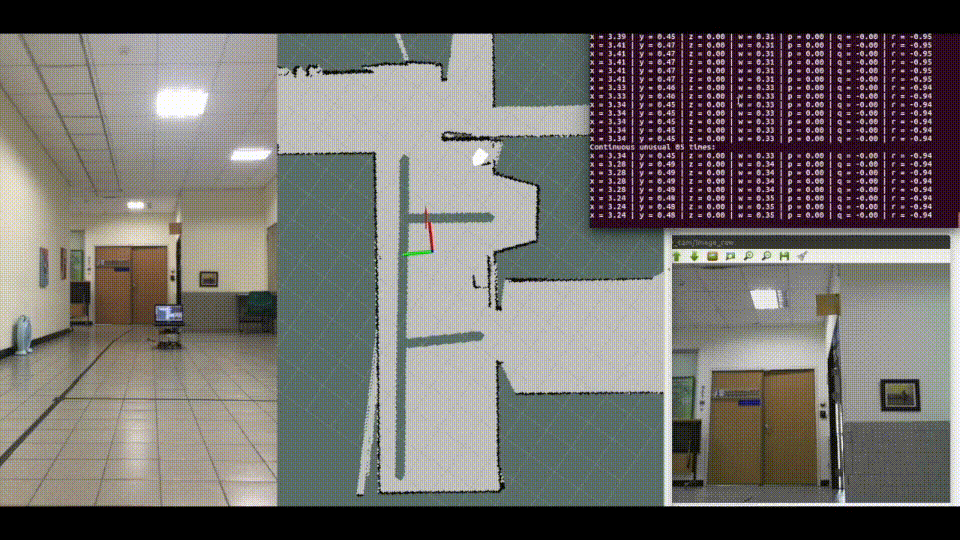
Using pose estimation model do robot indoor localization task
Keywords :
Deep Learning, Convolutional Neural Networks, Localization, Pose Estimation, Computer Vision
Pytorch, OpenCV, ROS
Python
Semantic Segmentation is a computer vision task that involves grouping together similar parts of the image that belong to the same class. For this project, we propose a simple convolutional autoencoder model to do foreground-background subtraction for small-scale images.
Achievement:
✓ Design and deploy "Autoencoder" for foreground-background subtraction
✓ Optimize loss function
✓ Data augmentation to improve accuracy
✓ Patents:
- Anti-cheating Method and Electronic Device (TW [TWI779566B] / CH), 2020

Foreground-background Subtraction
Keywords :
Deep Learning, Convolutional Neural Networks, Semantic Segmentation, Background Subtraction, AutoEncoder, Computer vision
Tensorflow, OpenCV
Python
Deep learning has demonstrated high accuracy in facial recognition in recent years and has been applied in various fields. This project uses an open-source machine learning algorithm for face recognition that only requires a single photo per person as data in order to improve understanding of this technology.
Achievement:
✓ Deploy with inference engine - OpenVINO

Facial recognition using inference engine
Keywords :
Deep Learning, Convolutional Neural Networks, Face Recognition, Computer vision
OpenVINO, OpenCV
Python, C++
